Today, a new OpenSSL security advisory came out and it patched my recent finding, Padding oracle in AES-NI CBC MAC check (CVE-2016-2107).
In this post, I will give some background on this attack and how I found it. Before reading the whole post, note that this vulnerability is very hard to exploit (even if it is given the high severity score). Also note that it is not a new general padding oracle attack with a new logo. It is just an oracle coming from an invalid check of decrypted message content, specifically introduced in OpenSSL (ok, if you really want to have a name for it, call it UnluckyHMAC ...because our HMAC is sad not to be able to validate bytes :) ).
I assume my readers are familiar with TLS, AES-CBC, padding oracle attacks, and post quantum crypto (ok, maybe you do not necessarily need the last one).
UPDATE: Today, I found some time to re-read some posts about CVE-2016-2107 and to my surprise, many posts claim OpenSSL provides a timing oracle, including Redhat or Cloudflare (otherwise a very nice post). This is NOT true. It is a direct padding oracle, see below.
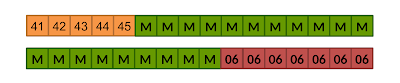 Note that (for the attack purposes) the encryptor can also choose a longer padding and add 23, 39, ...or 52 padding bytes. This means the following message contains valid padding as well:
Note that (for the attack purposes) the encryptor can also choose a longer padding and add 23, 39, ...or 52 padding bytes. This means the following message contains valid padding as well:


For now, you probably have some specific questions:
What if my server does not use AES-NI?
OpenSSL contains several places where Lucky13 had to be patched. This specific vulnerability only affects the AES-NI implementation. The implementation without AES-NI is not vulnerable, it was patched by Adam Langley, see https://www.imperialviolet.org/2013/02/04/luckythirteen.html
What if I send only one TLS record? (this would mean only 16 padding bytes need to be correct)
In case the server receives only one TLS record, it automatically rejects the message and closes the connection. The reason is that it does not make sense to decrypt and process the message further, since this message would not achieve 20 bytes, which are needed for MAC validation.
Was it easy to patch this vulnerability?
Yes. https://github.com/openssl/openssl/commit/70428eada9bc4cf31424d723d1f992baffeb0dfb
How about a proof of concept?
You can use TLS-Attacker to build a proof of concept and test your implementation. You just start TLS-Attacker as follows:
java -jar TLS-Attacker-1.0.jar client -workflow_input rsa-overflow.xml -connect $host:$port
In this post, I will give some background on this attack and how I found it. Before reading the whole post, note that this vulnerability is very hard to exploit (even if it is given the high severity score). Also note that it is not a new general padding oracle attack with a new logo. It is just an oracle coming from an invalid check of decrypted message content, specifically introduced in OpenSSL (ok, if you really want to have a name for it, call it UnluckyHMAC ...because our HMAC is sad not to be able to validate bytes :) ).
I assume my readers are familiar with TLS, AES-CBC, padding oracle attacks, and post quantum crypto (ok, maybe you do not necessarily need the last one).
UPDATE: Today, I found some time to re-read some posts about CVE-2016-2107 and to my surprise, many posts claim OpenSSL provides a timing oracle, including Redhat or Cloudflare (otherwise a very nice post). This is NOT true. It is a direct padding oracle, see below.
TLS and its MAC-then-PAD-then-Encrypt failure
In order to protect messages (records) exchanged between TLS peers, it is possible to use different crypto primitives. One of them is a MAC combined with AES in CBC mode of operation. Unluckily, TLS decided to use the MAC-then-PAD-then-Encrypt mechanism, which means that the encryptor first computes a MAC over the plaintext, then pads the message to achieve a multiple of block length, and finally uses AES-CBC to encrypt the ciphertext.
For example, if we want to encrypt five bytes of data and use HMAC-SHA (with 20 bytes long output), we end up with two blocks. The second blocks needs to be padded with 7 bytes 0x06.


For the encryptor, this process is quite obvious.
The decryptor has to be however very careful. He needs to first decrypt the message, check and unpad the last bytes, and finally verify the MAC. It is important that there is no leakage about the padding validity, i.e. the decryptor has to always proceed to MAC validation. In case of a failure, always the same error message should be returned. Otherwise, an attacker could execute padding oracle attacks.
The Lucky 13 attack showed that a tiny timing difference in message processing can lead to padding oracle attacks. Since Lucky 13 was applicable to the TLS standard in general, many developers patched their TLS libraries. However, it seems that not everyone evaluated the patch correctness...
Tests for Padding Oracles with TLS-Attacker
Very recently, I released my tool for TLS tests and fuzzing called TLS-Attacker. This tool allows developers to test their TLS servers with specific TLS messages, which can be sent in arbitrary order or with arbitrary modifications. This makes TLS-Attacker also a useful tool for development of simple proof-of-concept TLS protocol flows, or to test for padding oracle vulnerabilities.
I implemented padding oracle validity check with various attack vectors. These vectors include several invalid padding types known from the literatures, or from my previous work (see the code here https://github.com/RUB-NDS/TLS-Attacker/blob/master/Attacks/src/main/java/de/rub/nds/tlsattacker/attacks/impl/PaddingOracleAttack.java#L65). TLS-Attacker simply executes several handshakes and at the end it always appends an invalid TLS record. In a good case, the server always answers with a single alert message type ( BAD_RECORD_MAC). In a bad case, we can see more alert message types, which could lead to a direct padding oracle.
If you want to run the test, use TLS-Attacker with the following command (see also https://github.com/RUB-NDS/TLS-Attacker/wiki/Attacks):
java -jar TLS-Attacker-1.0.jar padding_oracle -connect $server:$port
I used TLS-Attacker and its padding oracle implementation to evaluate the newest OpenSSL version. To my surprise, at the end of the padding oracle test, I could see two different alert messages returned by the OpenSSL server. First, I thought that I am missing something and my implementation contains a huge bug again. However, it turned out TLS-Attacker works fine.
Btw, I am sorry, I removed the
code leading
to the OpenSSL vulnerability from my public TLS-Attacker version: https://github.com/RUB-NDS/TLS-Attacker/commit/9e1bd788b4e79d1445557523f6850e4145c55b20#diff-039b46965254b2a7453a11ab0ebdeef5L142
Otherwise, this would be easy to find by everyone ;)
The OpenSSL padding oracle bug
The best way to explain the problem is to give an example of a message triggering a different alert.
Given an attacker sends to the server a message decrypting to two blocks with an incomplete padding, the server responds with a RECORD_OVERFLOW alert. Example gives a message with 32 bytes of 0xFF padding.

As you can correctly see, this message lacks more than 200 padding bytes (0xFF means there should be 257 padding bytes), and a MAC. Therefore, it should be rejected. However, this is not the case for the OpenSSL AES-NI implementation. This implementation does not check whether there are enough data for MAC and padding validation. It just checks whether all the decrypted padding bytes are correct. If there are not enough padding bytes, it just omits further padding and MAC validation and proceeds with further internal steps in the record processing function. See the vulnerable code here: https://github.com/openssl/openssl/blob/b1a07c38540105077878ad80a6a87c96fdbc18f1/crypto/evp/e_aes_cbc_hmac_sha1.c#L739
OK, but where does the RECORD_OVERFLOW come from?
If such a decrypted message is further processed by the function tls1_cbc_remove_padding (file s3_cbc.c), this function resets the message size and computes it as follows:
rr->length -= padding_length + 1;
Note that in our case
the record length is 32 (two 16 byte blocks) and the padding length is 256. Thus, the record length variable underflows and becomes
rr->length = 4294967264
This also explains why we get the record overflow alert, triggered from
s3_pkt.c. There, we have a check whether the data decrypted message data is too long (probably this check was introduced by validate the decompressed data):
if (rr->length > SSL3_RT_MAX_PLAIN_LENGTH + extra) {
al = SSL_AD_RECORD_OVERFLOW;
SSLerr(SSL_F_SSL3_GET_RECORD, SSL_R_DATA_LENGTH_TOO_LONG);
goto f_err;
}
Since our record length variable is now really huge, the RECORD_OVERFLOW is returned.
For now, you probably have some specific questions:
What if my server does not use AES-NI?
OpenSSL contains several places where Lucky13 had to be patched. This specific vulnerability only affects the AES-NI implementation. The implementation without AES-NI is not vulnerable, it was patched by Adam Langley, see https://www.imperialviolet.org/2013/02/04/luckythirteen.html
What if I send only one TLS record? (this would mean only 16 padding bytes need to be correct)
In case the server receives only one TLS record, it automatically rejects the message and closes the connection. The reason is that it does not make sense to decrypt and process the message further, since this message would not achieve 20 bytes, which are needed for MAC validation.
Was it easy to patch this vulnerability?
Yes. https://github.com/openssl/openssl/commit/70428eada9bc4cf31424d723d1f992baffeb0dfb
How about a proof of concept?
You can use TLS-Attacker to build a proof of concept and test your implementation. You just start TLS-Attacker as follows:
java -jar TLS-Attacker-1.0.jar client -workflow_input rsa-overflow.xml -connect $host:$port
The xml configuration file (rsa-overflow.xml) looks then as follows:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<workflowTrace>
<protocolMessages>
<ClientHello>
<messageIssuer>CLIENT</messageIssuer>
<includeInDigest>true</includeInDigest>
<extensions>
<EllipticCurves>
<supportedCurvesConfig>SECP192R1</supportedCurvesConfig>
<supportedCurvesConfig>SECP256R1</supportedCurvesConfig>
<supportedCurvesConfig>SECP384R1</supportedCurvesConfig>
<supportedCurvesConfig>SECP521R1</supportedCurvesConfig>
</EllipticCurves>
</extensions>
<supportedCompressionMethods>
<CompressionMethod>NULL</CompressionMethod>
</supportedCompressionMethods>
<supportedCipherSuites>
<CipherSuite>TLS_RSA_WITH_AES_128_CBC_SHA</CipherSuite>
<CipherSuite>TLS_RSA_WITH_AES_256_CBC_SHA</CipherSuite>
<CipherSuite>TLS_RSA_WITH_AES_128_CBC_SHA256</CipherSuite>
<CipherSuite>TLS_RSA_WITH_AES_256_CBC_SHA256</CipherSuite>
</supportedCipherSuites>
</ClientHello>
<ServerHello>
<messageIssuer>SERVER</messageIssuer>
</ServerHello>
<Certificate>
<messageIssuer>SERVER</messageIssuer>
</Certificate>
<ServerHelloDone>
<messageIssuer>SERVER</messageIssuer>
</ServerHelloDone>
<RSAClientKeyExchange>
<messageIssuer>CLIENT</messageIssuer>
</RSAClientKeyExchange>
<ChangeCipherSpec>
<messageIssuer>CLIENT</messageIssuer>
</ChangeCipherSpec>
<Finished>
<messageIssuer>CLIENT</messageIssuer>
<records>
<Record>
<plainRecordBytes>
<byteArrayExplicitValueModification>
<explicitValue>
3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F
3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F
</explicitValue>
</byteArrayExplicitValueModification>
</plainRecordBytes>
</Record>
</records>
</Finished>
<ChangeCipherSpec>
<messageIssuer>SERVER</messageIssuer>
</ChangeCipherSpec>
<Finished>
<messageIssuer>SERVER</messageIssuer>
</Finished>
</protocolMessages>
</workflowTrace>
<workflowTrace>
<protocolMessages>
<ClientHello>
<messageIssuer>CLIENT</messageIssuer>
<includeInDigest>true</includeInDigest>
<extensions>
<EllipticCurves>
<supportedCurvesConfig>SECP192R1</supportedCurvesConfig>
<supportedCurvesConfig>SECP256R1</supportedCurvesConfig>
<supportedCurvesConfig>SECP384R1</supportedCurvesConfig>
<supportedCurvesConfig>SECP521R1</supportedCurvesConfig>
</EllipticCurves>
</extensions>
<supportedCompressionMethods>
<CompressionMethod>NULL</CompressionMethod>
</supportedCompressionMethods>
<supportedCipherSuites>
<CipherSuite>TLS_RSA_WITH_AES_128_CBC_SHA</CipherSuite>
<CipherSuite>TLS_RSA_WITH_AES_256_CBC_SHA</CipherSuite>
<CipherSuite>TLS_RSA_WITH_AES_128_CBC_SHA256</CipherSuite>
<CipherSuite>TLS_RSA_WITH_AES_256_CBC_SHA256</CipherSuite>
</supportedCipherSuites>
</ClientHello>
<ServerHello>
<messageIssuer>SERVER</messageIssuer>
</ServerHello>
<Certificate>
<messageIssuer>SERVER</messageIssuer>
</Certificate>
<ServerHelloDone>
<messageIssuer>SERVER</messageIssuer>
</ServerHelloDone>
<RSAClientKeyExchange>
<messageIssuer>CLIENT</messageIssuer>
</RSAClientKeyExchange>
<ChangeCipherSpec>
<messageIssuer>CLIENT</messageIssuer>
</ChangeCipherSpec>
<Finished>
<messageIssuer>CLIENT</messageIssuer>
<records>
<Record>
<plainRecordBytes>
<byteArrayExplicitValueModification>
<explicitValue>
3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F
3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F
</explicitValue>
</byteArrayExplicitValueModification>
</plainRecordBytes>
</Record>
</records>
</Finished>
<ChangeCipherSpec>
<messageIssuer>SERVER</messageIssuer>
</ChangeCipherSpec>
<Finished>
<messageIssuer>SERVER</messageIssuer>
</Finished>
</protocolMessages>
</workflowTrace>
It looks to be complicated, but it is just a configuration for a TLS handshake used in TLS-Attacker, with an explicit value for a plain Finished message (32 0x3F bytes). If you change the value in the Finished message, you will see a different alert message returned by the server.
Another useful check was implemented by Filippo Valsorda: https://twitter.com/FiloSottile/status/727609179872083968
Everything is insecure and every OpenSSL ciphertext can be decrypted... *
...ehm, no. To be honest, this bug is really hard to exploit (but I think still easier than Lucky 13), and can only be used in specific BEAST-like scenarios.
In such a scenario:
1) The attacker can force the victim to establish connections to the server (e.g., from a javascript)
2) he can intercept and modify TLS ciphertexts
3) he has knowledge about parts of the plaintext the victim sends to the server (e.g., the HTTP headers) and can control this plaintext
4) he wants to decrypt confidential data (e.g., cookies) and this data is located directly before the plaintext the attacker controls. This is needed in our specific case, where we need two valid blocks filled with valid padding.
For example, we have a scenario where the attacker forces the victim to visit amazon.com/test and inserts two blocks of valid padding (0x3F) directly behind the cookie (x0-xf). Assume the relevant plaintext blocks would look like this:

Block n: .. x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 xa xb xc xd xe Block n+1: xf 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F Block n+2: 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F 3F Block n+3: 3F .......
If the attacker knows these positions, and sends only encrypted blocks
(n+1) and (n+2) to the server, with a probability of 1/256, he receives a RECORD_OVERFLOW alert. This would mean that the last cookie byte became 0x3F. Otherwise, the last cookie byte is different and he needs to play with an initialization vector until he receives RECORD_OVERFLOW.
Once he knows the last cookie byte, he can force the victim to amazon.com/test2. This would shift the second last cookie byte xe to the block n+1, and we can again try to trigger construct a valid padding and trigger a RECORD_OVERFLOW.
The attacker can proceed further to decrypt the rest of the cookie bytes.
It is NOT a timing oracle
Many people thought that this bug provides just a timing oracle. However, this is not true and exploiting the server behaviour is much easier than measuring timing timing differences.
To explain why, let us get back to the explanation of how a TLS handshake works and how an attacker can provoke an invalid a TLS error.
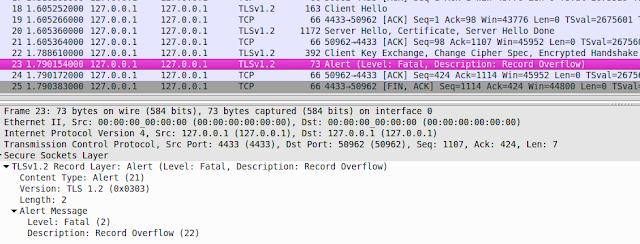
 |
| TLS RSA handshake and message exchange. All red messages are encrypted. |
The TLS handshake works (very briefly) as follows. First, the client and server exchange Hello messages where they agree on the TLS channel properties. Afterwards, the client sends a ClientKeyExchange message containing a premaster secret encrypted with the server's public key. The premaster secret is a secret used to derive all the keys needed for encryption and HMAC algorithms. It sends a ChangeCipherSpec message followed by a Finished message. The Finished message is the first message protected by the established HMAC (in our case, HMAC-SHA1) and cipher (AES-CBC). The server responds with a ChangeCipherSpec message and a Finished message. The Finished message is again protected with HMAC and encrypted.
From now on, both peers can exchange encrypted Application messages. If the attacker modifies the Application message sent by the client, a vulnerable server responds with a BAD_RECORD_MAC or RECORD_OVERFLOW alert. Of course, the attacker cannot see the message content since the alert message is also encrypted.
How can the attacker overcome this?
There are two useful TLS properties that we need to be aware of:
- The Finished message is encrypted with the same key as the Application message (in fact, both messages are sent over a record layer, which takes care of encryption).
- If the Finished message is modified by an attacker, the server responds with a plain alert message.
Now, you maybe already see the problem...
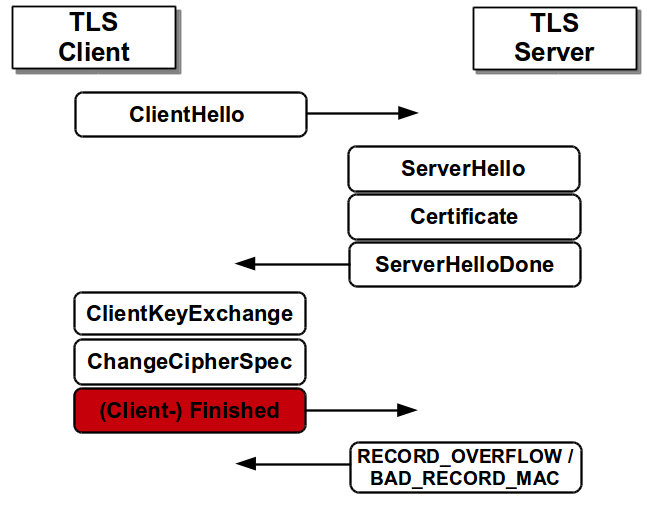 |
| TLS RSA handshake with an invalid Finished message: the server responds with a plain alert message. |
By executing the attack, our attacker proceeds as follows. He simply forwards all the messages sent by the client, up to the ChangeCipherSpec message. He then removes the ciphertext from the original client Finished message and instead, he inserts there the modified data from the Application message. The server attempts to decrypt this new Finished message, and responds with a plain alert message.
You can use TLS-Attacker and follow the TLS message trace with Wireshark. You will then see plain TLS alert messages.
BAD_RECORD_MAC...

...and RECORD_OVERFLOW
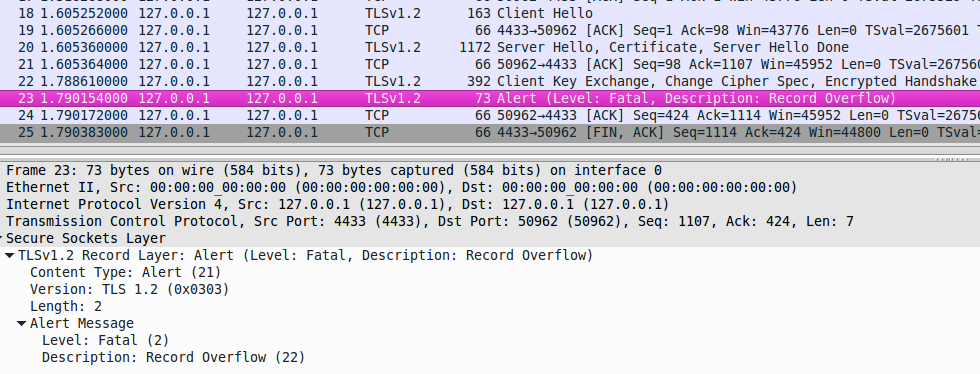
Lessons Learned
I think this specific bug on its own is not that interesting. It is just a simple padding oracle issue. However, it is interesting that this bug was introduced by patching the Lucky 13 attack and available in OpenSSL for more than 3 years. This means that the developers accidentally inserted a new more severe vulnerability (direct padding oracle) by trying to patch Lucky 13 (a rather complex timing attack).
OpenSSL is not alone. I found a similar problem in the MatrixSSL library, see https://github.com/matrixssl/matrixssl/blob/master/CHANGES.md. In that case, unfortunately, a bad patch of Lucky 13 lead even to a buffer overread vulnerability.
What we have learned from these bugs is that patching crypto libraries is a critical task and should be validated with positive as well as negative tests. For example, after rewriting parts of the CBC padding code, the TLS server must be tested for correct behaviour with invalid padding messages.
I hope TLS-Attacker can once be used for such a task.
It is also interesting to see that TLS concepts allow an attacker to force the to respond with plain Alert messages. I am not sure whether this is a protocol issue or not, and would like to have your opinion.
It is also interesting to see that TLS concepts allow an attacker to force the to respond with plain Alert messages. I am not sure whether this is a protocol issue or not, and would like to have your opinion.
...and of course, not to forget, we have learned again that using MAC-then-Encrypt is a bad idea, and it should better be deprecated.
* If I would like to get new Twitter followers and sell this bug with a new logo and name, I would probably claim this ;)